Partial Reconfiguration on FPGAs: When Earns Its Complexity
Introduction
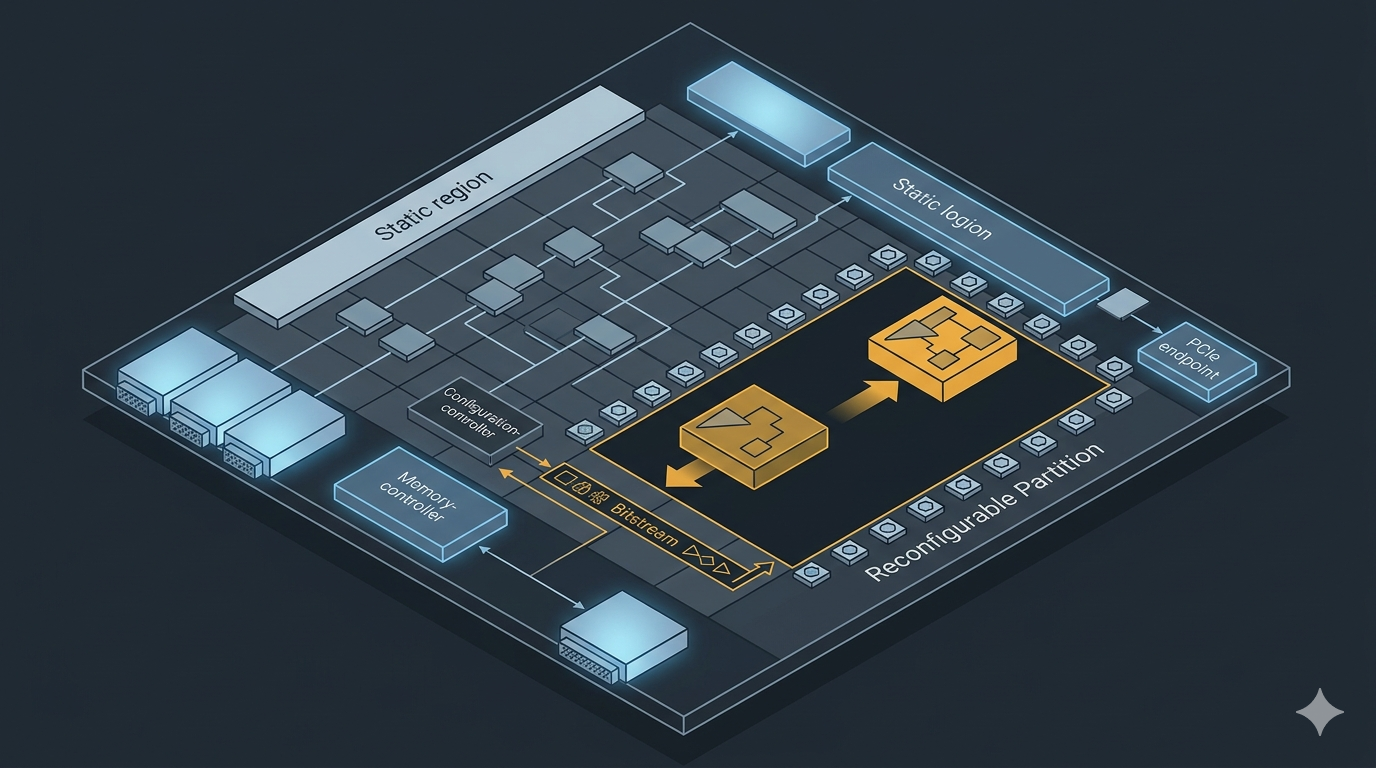
An FPGA bitstream is conventionally treated as monolithic: you compile one configuration, load it, and reconfiguring means a full device reload with all I/O dropping out. Partial Reconfiguration (PR) breaks that assumption. It allows a defined region of the fabric to be reprogrammed at runtime while the static portion — clocks, memory controllers, high-speed transceivers, PCIe endpoints — keeps running undisturbed.
That single property changes the economics of several designs. Instead of provisioning silicon for every function the system might ever need, you provision for the largest concurrent set and time-multiplex the rest. AMD/Xilinx now markets this capability as Dynamic Function eXchange (DFX), the name used in Vivado since roughly 2020, though the underlying mechanism — frame-based reconfiguration through the configuration port — is the same one engineers have used for over a decade. The catch is that DFX is not a checkbox feature; it imposes real constraints on floorplanning, timing, and verification that must be planned from the start.
What Partial Reconfiguration Actually Buys You
The value falls into four practical categories:
- Silicon and cost reduction. If functions A, B, and C are mutually exclusive in time, you size one Reconfigurable Partition (RP) for the largest of them rather than instantiating all three. This can drop you into a smaller, cheaper device.
- Maintaining live interfaces during a function swap. This is often the real reason to use DFX. You can replace a hardware accelerator without tearing down a PCIe link, a 100G Ethernet MAC, or a DDR4 controller in the static region. Full reconfiguration cannot do this.
- Power management. An unused RP can be loaded with a blanking (empty) module that gates clocks and minimizes dynamic power.
- Field adaptability and fault response. Algorithms, protocols, or accelerator kernels can be updated in the field, and in radiation environments, modules can be scrubbed or relocated for SEU (Single-Event Upset) mitigation.
How the AMD/Xilinx DFX Flow Works
A DFX design is partitioned into a static region and one or more Reconfigurable Partitions (RP). Each RP can host several Reconfigurable Modules (RM) — alternative implementations that share the same physical footprint and interface.
The flow has three structural requirements:
- A fixed boundary interface. Every RM in an RP must present identical port lists. The tool inserts partition pins — anchored routing points where static and reconfigurable logic meet.
- A physical region (Pblock) large enough to hold the largest RM, including its DSP, BRAM, and CLB needs.
- Per-configuration implementation. Vivado implements the static design once, then implements each RM in context, producing one full bitstream plus a partial bitstream per RM.
Floorplanning is done with constraints like the following:
# Tag the partition instance as reconfigurable
set_property HD.RECONFIGURABLE 1 [get_cells u_accel_rp]
# Constrain it to a physical region sized for the LARGEST RM,
# including the heterogeneous resource columns it needs
create_pblock pblock_accel
add_cells_to_pblock pblock_accel [get_cells u_accel_rp]
resize_pblock pblock_accel -add {SLICE_X40Y100:SLICE_X80Y199}
resize_pblock pblock_accel -add {DSP48_X2Y40:DSP48_X3Y79}
resize_pblock pblock_accel -add {RAMB36_X2Y20:RAMB36_X3Y39}
# Drive RM logic into a known reset state after each reconfiguration
set_property RESET_AFTER_RECONFIG true [get_pblocks pblock_accel]
# Align the region to clean reconfiguration frame boundaries
set_property SNAPPING_MODE ON [get_pblocks pblock_accel]
At runtime, partial bitstreams are pushed through a configuration port — typically the ICAP (Internal Configuration Access Port) on standalone FPGAs, or the PCAP path on Zynq/Zynq UltraScale+ devices. AMD provides the DFX Controller IP (formerly PRC) to automate the handshake. Each Virtual Socket Manager (VSM) handles one RP: on a software trigger it decouples the RP from the static logic, fetches the partial bitstream over an AXI master, streams it to ICAP, then re-enables the RP after reset.
// Illustrative bare-metal trigger for the AMD DFX Controller.
// Register offsets are device/IP-config dependent — check the PG.
#define DFX_CTRL_BASE 0xA0000000u
#define VSM_TRIGGER 0x00u // write trigger ID -> selects target RM
#define VSM_STATUS 0x04u // poll for RECONFIG/RESET completion
void dfx_load(uint32_t vsm_idx, uint32_t trigger_id) {
volatile uint32_t *vsm =
(uint32_t *)(DFX_CTRL_BASE + vsm_idx * 0x10u);
// The controller now handles: decouple -> DMA bitstream ->
// ICAP write -> RP reset -> recouple. No manual ICAP poking.
vsm[VSM_TRIGGER / 4] = trigger_id;
while (!(vsm[VSM_STATUS / 4] & 0x1u)) // wait for completion flag
; // production code should time out and check error bits
}
Reconfiguration latency is dominated by bitstream size and port throughput. A 32-bit ICAP at ~100 MHz delivers roughly 400 MB/s, so a 1 MB partial bitstream takes about 2.5 ms; bitstream compression and higher ICAP clocks shrink this. For UltraScale+, the MCAP path via PCIe can be considerably faster. These numbers matter: if your application needs a sub-microsecond function swap, DFX is the wrong tool.
Vendor Support Compared
| Vendor | Feature name | Representative families | Config path | Notes |
|---|---|---|---|---|
| AMD/Xilinx | Dynamic Function eXchange (DFX) | 7-series, UltraScale, UltraScale+, Versal | ICAP, PCAP, MCAP | Most mature; supports nested/hierarchical DFX and Abstract Shell for faster RM builds |
| Intel/Altera | Partial Reconfiguration | Stratix V, Arria 10, Stratix 10, Agilex | Dedicated PR region controller | Solid Quartus support; hierarchical PR available; flow differs in region/freeze handling |
| Microchip | Limited / flash-based | PolarFire, SmartFusion2 | Device-specific | Flash-based fabric makes SRAM-style dynamic in-fabric PR more constrained than on the two leaders |
| Lattice | Generally not offered | — | — | Small low-power devices target full reconfiguration instead |
In short, AMD/Xilinx and Intel/Altera are the two ecosystems where dynamic, in-system PR is a first-class, production-supported flow. AMD's tooling is the most feature-rich, particularly the Abstract Shell capability, which lets RMs be compiled against a minimal static context to cut implementation time on large devices.
The Hard Parts
DFX adds engineering effort that is easy to underestimate:
- Floorplanning and resource alignment. The Pblock must contain enough of each resource type (LUTs, DSPs, BRAM) in the right columns. A region that is large in slices but short on DSP columns will fail to place a DSP-heavy RM.
- Timing closure across a fixed boundary. Partition pins are anchored, so the static-to-RP interface timing is locked once the static design is implemented. Register the boundary on both sides; do not let combinational paths cross it.
- Isolation during the swap. While an RP is being reconfigured, its outputs are garbage. Decoupling logic (or the DFX Decoupler IP) must hold static-facing signals at safe values, and reset sequencing must bring the new RM up cleanly to avoid metastability.
- Verification combinatorics. With n RMs across m partitions you have up to n^m configurations. Each combination is technically a distinct implementation. Plan a tractable verification matrix early.
- Bitstream security. Partial bitstreams are an attack surface. Use the device's encryption and authentication; an unauthenticated partial load is a path to fabric-level compromise.
- Global resources. Clock buffers and certain hard blocks generally cannot live inside an RP, which shapes where you can draw partition boundaries.
Where It Pays Off in Practice
DFX earns its complexity in systems that are interface-anchored and function-diverse:
- Software Defined Radio (SDR). Swap modulation/demodulation or channel-filter cores while transceivers and the RF data path stay locked. This is a textbook fit: stable I/O, mutually exclusive processing chains.
- Datacenter and multi-tenant acceleration. Reload accelerator kernels (compression, crypto, ML inference) without dropping the host PCIe link — the model behind several cloud and hyperscale FPGA deployments.
- Adaptive video pipelines. Switch codecs or image-processing filters in a live stream while the DDR and display controllers in the static region keep running.
- Aerospace and defense. Reconfigurable payloads, adaptive signal processing, and SEU scrubbing in radiation environments where field flexibility and fault tolerance are requirements, not conveniences.
- Test and measurement instruments. A single device hosts multiple measurement personalities loaded on demand, reducing BOM cost versus separate hardware paths.
Conclusion
Partial Reconfiguration / DFX is a powerful but deliberate architectural choice, not a free optimization. It is the right tool when your system has a stable static core with expensive or persistent interfaces (PCIe, high-speed Ethernet, DDR, RF front-ends) and a set of mutually exclusive functions that are too large or too numerous to instantiate concurrently. In those cases it reduces silicon cost, enables field updates without link teardown, and supports fault-tolerant operation.
It is the wrong tool when function swaps must happen in microseconds (reconfiguration latency is in the millisecond range), when all functions must run concurrently anyway (no multiplexing benefit), or when the added floorplanning, isolation, and verification burden outweighs the resource savings on a small design. For mature, production-grade tooling, AMD/Xilinx DFX is the most complete option, with Intel/Altera a strong second; plan the partition boundaries, isolation, and bitstream security from day one rather than retrofitting them.
