Cache Coherency in Multi-Core Embedded Systems
Cache Coherency in Multi-Core Embedded Systems
Introduction
Multi-core is now standard at every tier of embedded design: symmetric application clusters (e.g., quad Cortex-A running Linux), asymmetric multiprocessing (AMP) pairings of an application core with a real-time core (Cortex-A + Cortex-M on the same SoC), and a growing population of DMA engines, GPUs, NPUs, and FPGA fabric that all touch the same DRAM. Every one of these agents may hold a private cached copy of a shared memory location.
The performance reason for caches is non-negotiable — external memory latency is two orders of magnitude above register access — but caching introduces a correctness problem the moment more than one agent caches the same address. The hardware and software mechanisms that keep those copies consistent are collectively called cache coherency. On a fully coherent SMP cluster the hardware handles it transparently; on the heterogeneous and AMP systems that dominate embedded, coherency is partial or absent across agents, and the firmware engineer becomes responsible for it. Getting this wrong produces intermittent data corruption that is timing-dependent, hard to reproduce, and frequently misdiagnosed as a DMA or compiler defect.
Where the problem comes from
Consider two cores, each with a private L1 data cache, sharing a variable X in DRAM (initial value 0).
- Core 0 reads
X-> a copy enters Core 0's cache (value 0). - Core 1 reads
X-> a copy enters Core 1's cache (value 0). - Core 0 writes
X = 1. With a write-back cache, this update stays in Core 0's cache; DRAM and Core 1's cache still hold 0. - Core 1 reads
X-> cache hit, returns the stale value 0.
The system now holds three different values for one address. The root cause is the combination of (a) private caches, (b) write-back policy, and (c) more than one agent with a copy. Two sub-problems must be solved:
- Write propagation: a write by one agent must eventually become visible to all others.
- Write serialization: all agents must observe writes to a single location in the same order.
A coherency protocol is precisely the mechanism that enforces these two properties.
Hardware coherency: snooping and directories
Hardware coherency tracks the state of each cache line and coordinates agents automatically.
- Snooping (bus-based): every cache monitors a shared interconnect. When one cache writes a line, it broadcasts an invalidate (or update); other caches holding that line drop or refresh their copy. Simple and low-latency, but broadcast traffic scales poorly beyond a handful of cores.
- Directory-based: a directory tracks which caches hold each line and sends point-to-point messages only to the relevant sharers. Scales to many cores at the cost of directory storage and added latency. This is the basis of modern many-core and chiplet interconnects.
Both are typically implemented with a MESI state machine — each line is Modified, Exclusive, Shared, or Invalid — or its extensions:
| State | Meaning | Memory up to date? | Other copies allowed? |
|---|---|---|---|
| Modified | This cache owns the only dirty copy | No | No |
| Exclusive | This cache has the only clean copy | Yes | No |
| Shared | One of possibly several clean copies | Yes | Yes |
| Invalid | Line not valid here | — | — |
| Owned (MOESI) | Dirty but shareable; this cache supplies data | No | Yes |
MOESI adds an Owned state so a dirty line can be shared between caches without a write-back to memory, reducing memory traffic. In the Arm ecosystem these protocols are realized by the ACE (AXI Coherency Extensions) and CHI (Coherent Hub Interface) interconnect standards, which is how a coherent cluster, an I/O-coherent DMA master, and an accelerator are tied together.
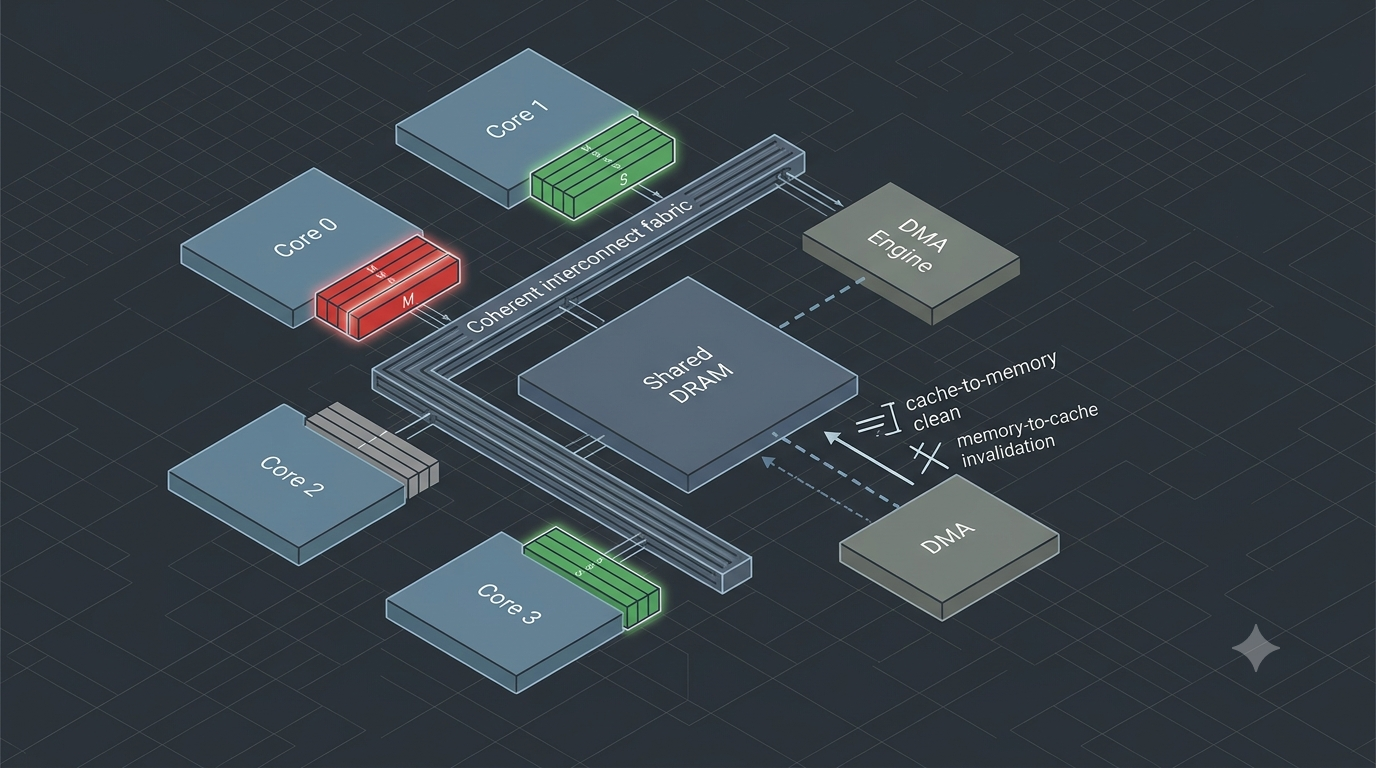
The non-coherent embedded reality
The critical point for embedded engineers: hardware coherency usually covers only the agents explicitly connected to the coherent interconnect — typically the application-core cluster. It often does not cover:
- a DMA engine writing into DRAM that the CPU has cached (the common case),
- the real-time core in an AMP pair sharing a buffer with the application core,
- an FPGA fabric master or accelerator attached to a non-coherent port,
- memory accessed by the CPU before the MMU/MPU and cache attributes are configured.
In these systems the cache is not kept consistent automatically, and the firmware must enforce coherency explicitly through cache maintenance operations.
Software-managed coherency: clean and invalidate
Two primitive operations, applied at cache-line granularity, do the work:
- Clean (flush): write any dirty cache line back to memory. Used before an external agent reads a buffer the CPU produced.
- Invalidate: discard a cache line so the next access re-fetches from memory. Used before the CPU reads a buffer an external agent produced.
The canonical DMA sequences are therefore:
- CPU -> device (transmit): CPU fills buffer -> clean the buffer range -> start DMA. The device reads correct data from DRAM.
- device -> CPU (receive): invalidate the buffer range -> start DMA -> device writes DRAM -> CPU reads (cache miss forces a fresh fetch). Invalidating before the transfer avoids a dirty line being evicted on top of freshly DMA'd data mid-transfer.
The hazard that catches engineers is granularity: maintenance acts on whole cache lines (commonly 32 or 64 bytes). If a DMA buffer shares a cache line with an unrelated variable, invalidating the buffer can discard a pending write to that neighbor, and cleaning the neighbor can overwrite DMA'd data. Buffers crossing a non-coherent boundary must be cache-line aligned and padded to a multiple of the line size.
Coherency is not memory ordering
These are distinct properties and require distinct mechanisms; conflating them is a frequent source of defects.
- Coherency concerns multiple cached copies of the same address.
- Memory consistency / ordering concerns the order in which accesses to different addresses become visible. Out-of-order cores and store buffers can reorder visible accesses even on a fully coherent system.
A flag-then-data handoff (buffer filled, then ready = 1) is correct only if a barrier prevents the ready write from becoming visible before the buffer writes. Coherency alone does not guarantee that ordering. The tools are memory barriers (Arm DMB/DSB), C11 <stdatomic.h> with explicit memory orders, and — separately — the compiler barrier that prevents the compiler from reordering or eliding accesses. volatile provides neither cache coherency nor inter-core ordering; it only prevents the compiler from caching a value in a register, which is necessary but far from sufficient.
Cache-aware C patterns
1. DMA buffer with correct alignment and maintenance (Cortex-M7/A, CMSIS-style):
#define CACHE_LINE 32u
#define ALIGN_CL __attribute__((aligned(CACHE_LINE)))
// Padded to a whole number of lines so maintenance never touches a neighbor.
static ALIGN_CL uint8_t rx_buf[((RX_LEN + CACHE_LINE - 1) / CACHE_LINE) * CACHE_LINE];
void dma_receive_start(void) {
// Discard any stale cached copy BEFORE the device writes DRAM,
// so the later CPU read is forced to miss and fetch fresh data.
SCB_InvalidateDCache_by_Addr((uint32_t *)rx_buf, sizeof rx_buf);
dma_start(rx_buf, sizeof rx_buf); // device now owns the buffer
}
void dma_transmit(const uint8_t *src, size_t n) {
memcpy(tx_buf, src, n); // CPU produces data (may sit in cache)
// Push dirty lines to DRAM BEFORE the device reads them.
SCB_CleanDCache_by_Addr((uint32_t *)tx_buf, n);
dma_start(tx_buf, n);
}
2. Eliminating false sharing. Two cores writing different fields that share one cache line force constant invalidation traffic even though there is no logical conflict (false sharing). Pad each hot, per-core field onto its own line:
struct percpu_counters {
_Alignas(64) volatile uint64_t core0_count; // own cache line
_Alignas(64) volatile uint64_t core1_count; // own cache line, no false sharing
};
3. Correct cross-core handoff with C11 atomics (coherent SMP):
#include <stdatomic.h>
uint8_t buffer[LEN];
atomic_int ready = 0;
// Producer core
void produce(void) {
fill(buffer, LEN); // 1. write payload
atomic_store_explicit(&ready, 1, memory_order_release); // 2. publish: payload visible first
}
// Consumer core
void consume(void) {
while (atomic_load_explicit(&ready, memory_order_acquire) == 0) { }
use(buffer); // acquire pairs with release: payload guaranteed visible here
}
The release/acquire pair enforces the ordering that coherency by itself does not. On a non-coherent AMP boundary this same handoff additionally requires clean on the producer side and invalidate on the consumer side around the buffer, plus a DSB to ensure the maintenance completes before the flag is published.
4. Shared control structure in non-cacheable memory. For small, frequently-updated shared structures crossing a non-coherent boundary, mapping the region as non-cacheable (via MMU/MPU attributes) removes the maintenance burden entirely, trading per-access latency for simplicity — appropriate for low-traffic mailboxes, not for bulk data.
What the programmer should remember
- Identify every shared region and which agents cache it; coherency is automatic only inside the hardware-coherent domain.
- Across a non-coherent boundary, apply clean-before-device-read and invalidate-before-CPU-read, and align/pad buffers to the cache line.
- Treat coherency and ordering as separate problems: use atomics/barriers for ordering, cache maintenance for coherency.
- Do not rely on
volatilefor either; it is a compiler directive, not a hardware coherency or ordering mechanism. - Watch cache-line granularity for both maintenance correctness and false-sharing performance.
Conclusion
Cache coherency is the guarantee that multiple cached copies of one memory location stay consistent. In symmetric application clusters this is handled by hardware protocols (MESI/MOESI over snoop or directory interconnects, exposed in Arm systems as ACE/CHI), and the engineer mostly needs correct memory ordering via atomics and barriers. In the heterogeneous and AMP systems that characterize embedded — CPU plus DMA, accelerators, FPGA fabric, or a real-time core on a non-coherent port — coherency is partial or absent, and the firmware must enforce it explicitly with cache clean/invalidate operations, cache-line-aligned buffers, and barriers.
Rely on hardware coherency when all relevant agents sit inside the coherent domain and the design is genuinely SMP; here, manual cache maintenance is unnecessary and risks errors. Switch to explicit software-managed coherency the moment a non-coherent agent shares a buffer, and reach for non-cacheable mappings only for small, low-traffic shared structures where the maintenance overhead outweighs the access-latency cost. In all cases, keep coherency and memory ordering as separate concerns with separate tools — that distinction prevents the largest share of multi-core data-corruption defects.
References / Further Reading
- Arm Limited. (2023). AMBA AXI and ACE Protocol Specification (ARM IHI 0022). Arm Developer Documentation.
- Arm Limited. (2021). AMBA CHI Architecture Specification (ARM IHI 0050). Arm Developer Documentation.
- Sorin, D. J., Hill, M. D., & Wood, D. A. (2011). A Primer on Memory Consistency and Cache Coherence. Morgan & Claypool (Synthesis Lectures on Computer Architecture).
- Arm Limited. (2020). Cortex-M7 Devices Generic User Guide — Cache maintenance operations. Arm Developer Documentation.
- ISO/IEC 9899:2018 (C17), Clause 7.17 — Atomics
<stdatomic.h>.
